
Building a Youtube Music Recommender: from scratch to deploy
![]()
Overview
On this article, I`ll comment some details of a simple solution I built to recommend Youtube music videos to myself. You can check out the deployed solution on Heroku at Youtube Music Recommender. I know, it is not beautiful. Maybe one day I will develop my front-end skills.
Heroku: https://thawing-shore-99052.herokuapp.com/
Then, the main idea here is to go from scratch to deployment. Mainly, this process will include all these steps:
- Scrapping video data from Youtube pages;
- Extracting the video information from each page;
- Preprocess data from each video into a single dataset;
- Manually label some of samples, active learning the rest;
- Extract features from the dataset;
- Train a Random Forest and a LightGBM model and ensemble them;
- Build a simple app to serve the model through Heroku.
Also, if you want to check out the code, I will be citing which script is used on each step.
Code: https://github.com/lmeazzini/youtube-recommender
Scrapping video data from Youtube pages
First of all, we need data! To get some data, I scrapped youtube pages by querying on Youtube search. Since I am looking for music to recommend to myself, I used six queries:
‘Folk rock’, ‘Classical guitar’, ‘Acoustic rock’, ‘Orchestral rock’, ‘Cello songs’ and ‘Brazillian rock’
Then, I saved the first 100 pages of each query. This is done in “search_data_collection.py” script.
Extracting the video information from each page
Now we have data from Youtube search pages, we need to extract information from the videos present on those pages. To do so, I made a parser with BeautifulSoup.
This parser just saves the link, title and query used for each video on the 600 pages. Also, since there is a possibily of videos been duplicated, I dropped the duplicates. This is done in “search_data_parsing.py” script.
Preprocess data from each video into a single dataset
From the parsed data, we are able to web scrap each video. There is much information here, most of the features we can get are from this step. Since this is a simple solution and I did not spent a lot of time engenieering features I used just a few of the possibilities.
There are 2277 videos totally, then this script takes a quite longe time to run, ~2h. The script name is “video_data_processing.py”
Manually label some of samples possibly with active learning
The most tedious and boring part of this work. I had to get labels. So, I opened the raw_data file generated by the previous step on sheets and added a “y” column and manually filled 1000 rows with 0 or 1.
With the labelled data, it is possible to train a Random Forest model and the features extracted on the next step and use this model to identify which samples are the hardest to classify (~0.5 output), then I manually labelled 200 of the samples identified by active learning.
The active learning helps a lot to mitigate the labelling cost. However, the labelling time I was expecting to spend was less then I imagined, so I ended manually labelling everything.
Extract features from the video data
Now, each row of our dataset is a video with its data, like title, number of views, author, description, video height, video width and other information. From these fields, I made feature engineering to extract some features that can be helpful to later.
This way, I extracted the number of views, view per day, video resolution and made a Bag of Words (BoW) with the title string. Surely, there are much more features that could be extracted, especially from video description and video tags. However, I left a more deep feature engineering to future works.
Train a Random Forest and a LightGBM model and ensamble them
With the extracted features and the labels, we can split the dataset in train and validation. I chose not to make a test set, leaving the ultimate validation to production data.
First I trained a LightGBM model optimizing its parameters with a bayesian optimization along with some data pre-processing parameters (like n_gram range for BoW). Then, the Random Forest model was trained with the same pre-processing parameters found on bayesian search. For more details, you can check the implementation. I looked for an ensemble of these two models giving a weight to each model.
To measure how well the model is performing, I chose not to use precision, recall and F1-Score. Since the problem involves a recommendation, the final output should be a ranking of the most relevant recommendations (output closer to 1). Then I used the average_precision_score, roc_auc and log_loss to better evaluate the model.
Also, I made a Learning Curve Analysis (LCA) to check if the data used was enough to have a consistent prediction. The ROC curve and the LCA can be seen on the figures below. The feature extraction and the modelling is on “final_model.py”
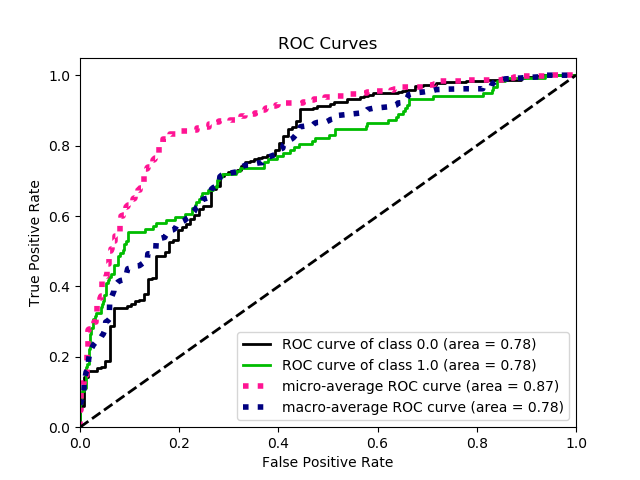
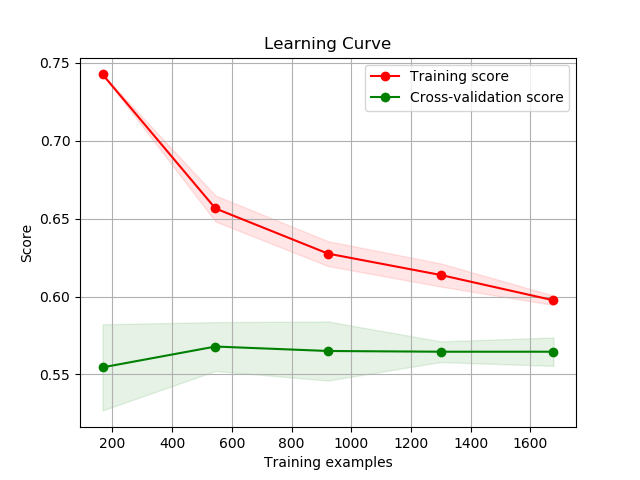
Build a simple app to serve the model through Heroku
Now that we have our model, we can make an application to predict on production data. Since our data is from youtube searches, if we use the same queries used to make the dataset, we would probably get the same or almost the same videos used to train/validate the model. Then I changed most of the queries to get different videos at the application.
This process includes an application (app.py) built with Flask. This script is responsible to call the functions to scrap new data, treat it and use the saved model to predict the output and finally, make the .html file to present the final output. The scrapped data is pre-processed and stored on a SQLite database and then queried to make predictions, this way later I can insert new data to the database and easy re-run the application.
To deploy it, I used Docker and Gunicorn. There is a Dockerfile with the configuration on the deploy folder. You can easily run a docker locally or even deploy it through Heroku, which I have done following the guide on Heroku documentation.
You can see the deployed application screenshot below:
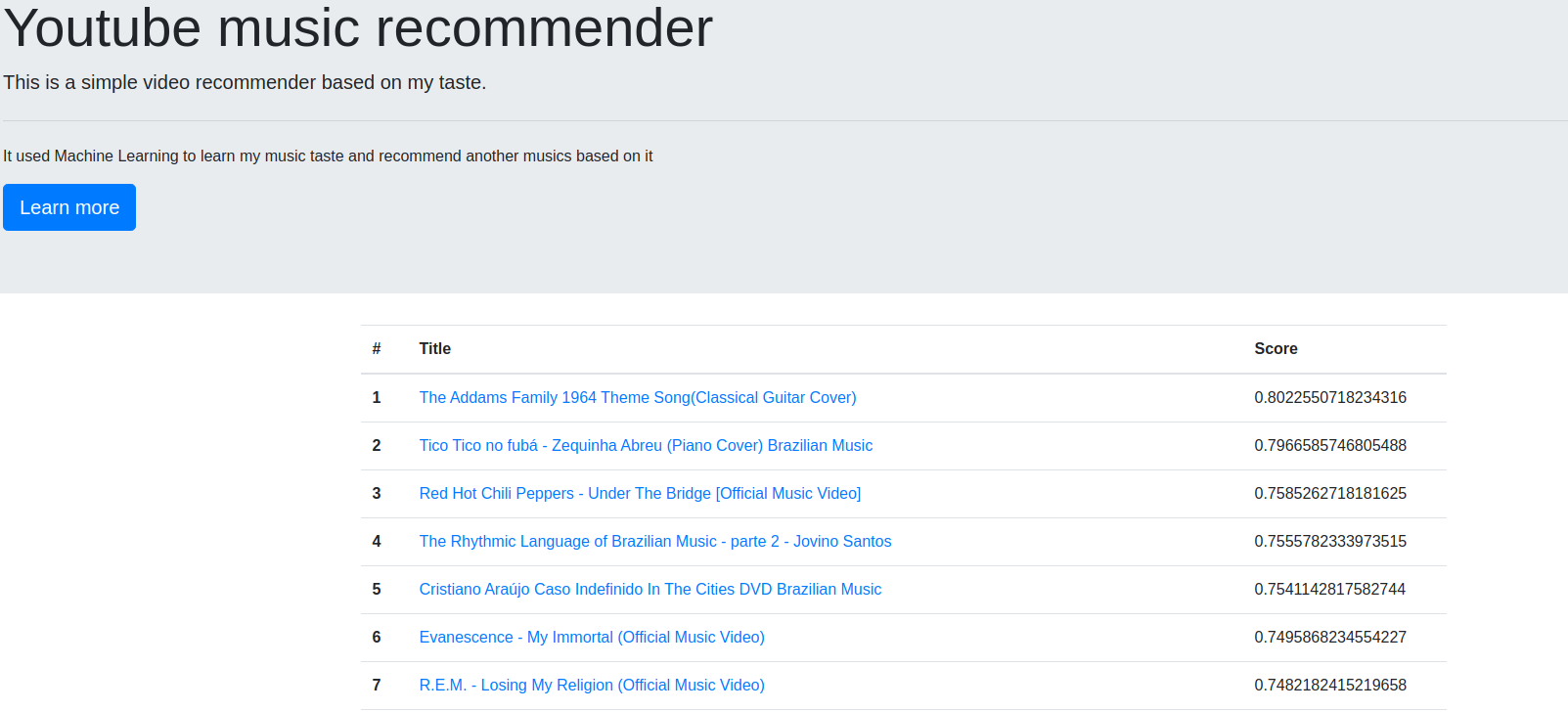
However, if you open it now probably the music list will be the same or quite similar to the screenshot. This can happen due to music do not change a lot over time and, the model just makes a re-classification when I want; there is no re-train routine scheduled.
Conclusion
Looking at the model predictions at production there a clear bias. A lot of the recommend videos have the String “Official Music Video” on the title. Probably this is a heavy feature that does not make a lot of sense. Many improvements can be made to improve the model performance and better understand the predictions.
Hope this article gives ideas and helps anyone who reads it. Again, this is article is not describing every step, however, the code is available at GitHub.